Homework 2: Guided Generation
Now that you know how to prompt an LLM from HW1, we will be using some guided story generation techniques from Module 2. In this homework, you will be following a generation pipeline inspired by the Plan-and-Write system. In their work, they generated keywords from a title and then generated a story from the keywords. They tried both dynamic and static schemas to integrate the planning into their generation pipeline. This homework will focus on the “static” schema but use a pre-trained LLM instead of their RNN model.
Learning Objectives
For this assignment, we will check your ability to:
- Prompt an LLM to generate stories given varying amounts of context
- Implement NLP evaluation metrics using existing libraries
- Compare the quality of guided vs unguided story generation
- Determine the adequacy of automated metrics like BLEU and ROGUE for creative evaluation
What to do
Getting Started
Like in the last homework, you will be using a Python notebook, but instead of using OpenAI’s suite of models, we’re going to use Mistral AI’s Mistral 7B model. Again, you can run in your local environment or upload it to Google Colab or DeepNote to do the assignment online.
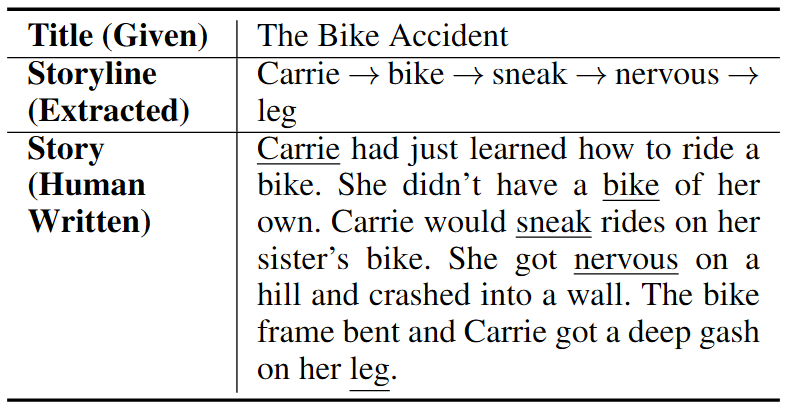
You will be using a portion of the data from the original Plan-and-Write work. I have already setup the data in the notebook. You will be using the stories, their titles, and the keywords they extracted. And you will only be looking at 20 stories from the dataset.
1) Generating new stories
In the notebook, you are given a series of functions that will retrieve the story data for you.
load_datawill return a list of all of the data in the file.get_storywill return a list of the sentences in the story.get_titlewill return the title of a story from a given line.get_keywordswill return the keywords of a story from a given line. Note that there may be more than one keyword per sentence!
I have taken 20 stories from the original dataset for you to work with.
You will be generating stories for all 20 prompts in two ways (40 generated stories in total):
- Unconditioned: Given a title, generate a 5-sentence story
- Conditioned: Given a title and keywords, generate a 5-sentence story where each keyword corresponds to a sentence in the story – this will be similar to the method in the paper
You are welcome to use any prompting techniques (e.g., zero-shot, few-shot, chain-of-thought). Like in HW1, it will be beneficial for you try multiple prompts until you get the best results, even if it’s just changing the wording of the prompt. However, you are only required to show your final prompt for both conditioned and unconditioned generation.
reader in the load_data() function. You can use a story from any other index outside of [:20] for your prompts.
2) Evaluate stories
You will evaluate the stories in a few different ways: a) BLEU - precision using n-grams b) ROUGE - recall of n-grams
N-grams are a common unit in NLP for talking about words that appear next to each other, where the n denotes how many words. For example, the sentence “The dog was really happy” contains:
- The unigrams
The,dog,was,really, andhappy - The bigrams
The dog,dog was,was really, andreally happy - The trigrams
The dog was,dog was really, andwas really happy - etc.
BLEU and ROUGE are common evaluation metrics used in NLP. BLEU was created to evaluate how accurate machine translation (computational translation of one human language to another) systems were. ROUGE was created to evaluate generated summaries of text.
You will implement BLEU and ROUGE using the following libraries:
- BLEU - https://www.nltk.org/api/nltk.translate.bleu_score.html
- ROUGE - https://pypi.org/project/rouge-score/
And you should calculate BLEU-1, BLEU-2, ROUGE-1, ROUGE-2, and ROUGE-L comparing both the controlled generation vs original story and uncontrolled generation vs original story. Specificially, the BLEU will be modified n-gram precision. Calculate these scores over each pair of sentences in the data and then average across the 20 stories. You will be implementing the BLEU and ROGUE functions to compare the sentences one-by-one in the stories and return an average across the 5 sentences.
uncontrolled_stories and controlled_stories. Before running these generated stories through BLEU/ROUGE, you will need to cut off the prompt since it will return the entire string with your prompt + the generated story after that.
Keep adjusting the prompt until you can consistently generate 5-sentence stories, but if you’ve tried a bunch of things and are still unable to get it to produce 5 sentences, evaluate on whatever sentences it generates. You can “pad” the story with empty strings to compare against with BLEU/ROUGE.
3) Analysis
Please answer the following questions in a separate document and save it as a pdf. Each answer should be a few sentences long.
- Simply reading the generated stories:
- a) What is the quality of the stories overall? (2 pts)
- b) How do the compare across the conditions? (2 pts)
- c) Which of the two conditions produced better stories? Why? (2 pts)
- What prompting techniques did you find work the best? (2 pts)
- Did the prompt need to be significantly altered to work well with the different inputs? Why? (2 pts)
- Higher BLEU and ROUGE scores mean better matches. Were there any interesting patterns that you can see with the BLEU and ROUGE scores? (2 pts)
- Did the BLEU/ROUGE correlate with your subjective analysis (just reading)? Why or why not? (2 pts)
- Are BLEU/ROUGE sufficient metrics for evaluating these stories? Why or why not? (2 pts)
What to submit
You should submit
- your completed Python Notebook, and
- a pdf of your answers to the questions in part 3 (analysis) to Blackboard. You can work in pairs.
Grading
- Generate stories using only titles (5 pts)
- Generate stories using titles and keywords (5 pts)
- Write functions for BLEU and ROUGE (4 pts)
- Analysis (16 pts)
Recommended readings
| Plan-And-Write: Towards Better Automatic Storytelling - Lili Yao, Nanyun Peng, Ralph Weischedel, Kevin Knight, Dongyan Zhao, Rui Yan. AAAI 2019. |
| Mistral 7B - Albert Q. Jiang, et al.. arXiv 2023. |